Software design and software architecture are topics which are sometimes associated with distant, slightly mad geniuses, living in an ivory tower and regularly throwing UML diagrams to their ground crew of “normal” developers. They are seen as arcane knowledge which can only be absorbed by the most experienced, most talented “10x developers“, “rockstars” and “ninjas”.
From my experience, this point of view couldn’t be farther from reality. On the contrary I see software design and architecture as fundamental parts of any kind of development work. The moment we start writing code, we will make decisions and are creating software design, no matter if we are aware or not.
Of course there might be guidelines, there might be an architecture given by others, there might even be detailed API descriptions and an abstract design which paints the big picture, but in the end the little, daily decisions will have a huge impact on the result.
Understanding the rules of good software design is therefore a topic which affects developers of any skill and experience level.
Knowledge in that field will be extremely beneficial for every task related to software development.
Four Rules of Simple Design
Kent Beck, developer of Extreme Programming (XP) and Test-Driven Development (TDD), came up with four rules of simple software design in the late 1990s, which Martin Fowler expresses like this:
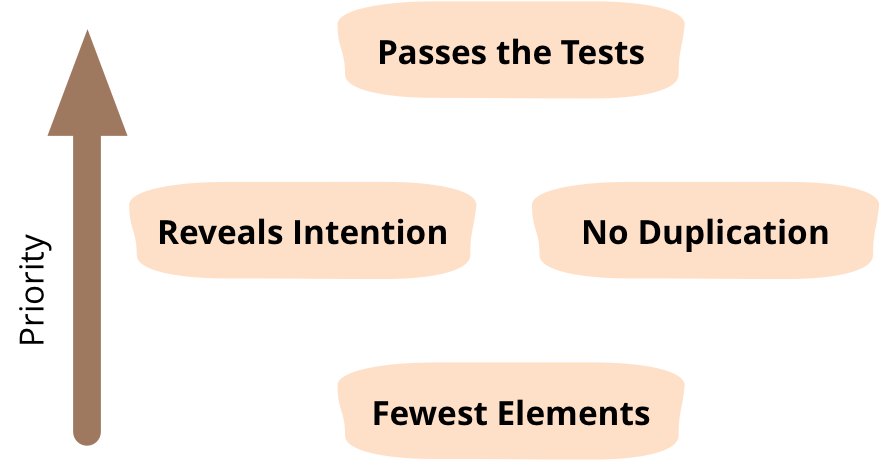
Martin gives a great, comprehensible description in his article about the “BeckDesignRules” which is also the source of the picture above.
I will try to take a deep dive into these rules, their spirit and how they can be practically done in database development. There is also much personal interpretation from my side and I’m not entirely sure whether Kent Beck would agree on all of my thoughts (of course I hope so).
I will split this up into several blog posts (you wouldn’t believe how hard it is anyway to keep my personal goal of one post per month) and today’s post will cover the first, probably most important and impactful of Beck’s design rules:
Passes the Tests
This one is clearly about Unit-Testing, Test-Driven Development and lots of green lights in your testing report, isn’t it? It means that good software design must adopt specific patterns from XP or other agile methodologies, right?
While I can’t tell what Kent Beck had in mind exactly when he came up with these rules, I think this interpretation is way too short-sighted and narrow. Because if we talk about passing the tests we first have to think about the tests:
What are the tests the software has to pass? What are the requirements? What should my software, my function, my code do?
And suddenly we left the layer of dogmatic, technical discussions about frameworks and methods and entered the field of “business knowledge” or “domain knowledge”. This is the layer which has to be the source for our definition of “tests”. This is the layer which will provide the most value.
Our software, after all, exists to solve a specific problem which will most likely be a business problem. Without knowledge about the problem and its environment, our chances to solve the problem are limited at best, no matter which agile method we use, which database managagement system or which language.
‘A rewrite will end up with the same problems as the original unless you close the understanding gap’ – @sarahmei via @einarwh at #NDCOslo pic.twitter.com/7iJinUotIR
— Peter Hilton (@PeterHilton) June 13, 2018
It’s one of our most important tasks as developers to close these understanding gaps, to get knowledge about the problem’s domain.
Therefore our duties are not only to learn about algorithms, normal forms and indexing strategies but also to learn about our customers, to ask questions and to adopt the viewpoint of people who will end up using our software.
And that’s not even enough: as database developers this also means that we not only need to understand our data model but also need decent knowledge about how the application that will use our database works.
If we design a model or create a functionality the application is not able to use, it’s not “that stupid app developer’s fault” but a lack of domain knowledge on our side.
It’s also a failure of our entire team, not any individual members.
Even if we consider the functionality or model to be a good solution to the underlying problem and what needs to be changed is the application, we have a responsibility to communicate our point of view in an empathetic and understandable way.
Definition of tests
When we know enough about the problem and the things our software needs to do, we can start to define the tests our programs need to pass. This definition can be similar to the definition of done in agile methodologies, a formal contract specification or functional requirement we agreed upon with our customer (although that will not be detailed enough in most day-to-day problems) or just a picture in our head, depending on the circumstances.
The more complex a problem or functionality is, the more beneficial it is to have the defintion and tests written down in some way.
They can be written as unit-tests, as formal design-by-contract specifications but also as list of requirements on a wiki-page.
Writing down things (getting them out of your head) will also identify gaps in your thinking and increase your domain knowledge.
Especially when dealing with legacy code I found it extremely helpful to analyse existing code line-by-line and write it down in a non-code way. After that I can often identify logical problems and extract definitions for tests more easily, particularly if the legacy code to deal with is very verbose, created under unhealthy time pressure or contains changes of many different people with different philosophies and experience levels.
Each approach to recording tests has its strengths and weaknesses. Before insisting on any one method, evaluate your situation and see how your needs align with each approach. Teams vary in experience, projects vary in maturity and quality, companies vary in available budget and established culture.
Making thorough testing a part of your team’s culture can take time. Focus on the next step you need to take on the journey – don’t worry about how far you are from the ideal (ideals are very much dependent on the circumstances by the way).
Passes all the tests
There is no “some” in “Passes the tests”. Beck’s design rules place a strong priority on quality. Our software or functionality needs to pass all the tests before we hand over the application to our users. Otherwise, what’s the point of defining and writing the tests?
More than anything else, this involves a mindset of “everything matters”.
Don’t accept failing automated tests. Don’t accept typos when you see them. Don’t accept an error thrown by your application.
It’s very easy and sometimes tempting to ignore things that don’t have an immediate, big impact. But these little things can pile up very quickly and cause a rotten smell of bad quality for your users and customers. A spelling mistake in a prominent position is like a hair in your spaghetti: it’s not a major issue (compared to, say, finding a bug in your soup), but it will leave you feeling very uncomfortable about taking the next bite.
Refusing to ignore seemingly “minor” issues doesn’t mean that you have to fix them immediately (although that can be a very effective approach, depending on the circumstances). It simply means that you don’t ignore them. File a bug, write yourself a note or speak with a colleague who’s currently working on that part of your application.
The more disciplined you are about demanding the highest quality from your own code, the more you will come to be relied upon by others to help them produce top-notch, well-tested code as well.
Expecting the unexpected
“Passes the tests” does not only include the things your program should do but also the things that should not happen. To harden our application and create a great product we need to think about the things that can go wrong.
What if we get a negative number? What if a certain column is NULL? What if the select returns no rows? What if it returns more than one?
We might have defined the “happy-path” of our software and verified it’s working as it should, but dealing with the consequences of unwanted input or state is equally important.
Unwanted behaviour – no matter if it’s due to a bug in functionality or the application reacting badly on erroneous input – will always lead to user frustration (and therefore to loss of the most valuable currency a company has: trust).
Especially in the context of database development unwanted or unexpected behaviour can lead to serious implications like data loss or corrupt data – things which are very hard to repair afterwards.
Limiting the scope
Have you worked on a project that seemed reasonable and manageable at first, but then became a nightmare due to unclear definitions, requirements and uncontrolled growth (aka scope creep)?
If so, resist the temptation to ignore careful design in your panic. In most cases, even though you might feel better for a short duration, you will pay a big price for unmaintainable code in the medium and long run (I say in most cases here because there are situations where “just getting the job done” is a pragmatic and reasonable approach, but they are very, very few from my experience).
Instead, you should have a clear agreement within your team and, even more importantly, with your users about how to manage scope. How do you all evaluate together new requests? How do you decide which should be worked on, which can be delayed to the next release?
You may also need to limit your scope to satisfy “Passes (all) the tests”.
A designer knows he has achieved perfection not when there is nothing left to add, but when there is nothing left to take away.
— Antoine de Saint-Exupery
Define what your software should do and narrow it down.
If your software manages the vacation of members of the imperial army, it doesn’t necessarily need to be able to manage the (probably totally different) vacation rules of the rebels – if there are any.
It definitely doesn’t need to know about the history of sith (even if some national holidays are named after the most powerful sith). And if it’s not likely that we are about to sell our software to both, the imperium and the rebels, we should not start with thousands of abstractions and configuration options to support the specific vacation rules of every party in that galaxy far, far away.
Some features are not debatable beause they are strongly requested by the customer or essential to solve the existing problem. But some (especially the ones which include high uncertainties) can probably be delayed until we have grown a better understanding of the problem domain, which will then lead to better decision making. Others might fall into the category of YAGNI (You aren’t gonna need it) and can be skipped completely.
Be eager to drop complexity! If there is no compelling need to do it in the more complex, more generic way, don’t do it. You can always increase complexity later if you have increased your knowledge and mastered the basic challenges. But you will have a hard time going with the full-blown approach from day one. And there is a high chance you will end up with software including a bunch of non-tested features and a bunch of others that nobody needs – especially if the former don’t work correctly.
The power of databases
A great way of keeping your code simple, limiting your scope and therefore reducing maintenance cost in the future is to limit uncertainties.
If you happen to be using a relational database and have your business logic located there (which I assume in this blog post), you will find it packed with immensely powerful tools to do just this. Two of them: the relational model and constraints.
You expect a certain column to have a specific range? Assure it by creating a constraint. You expect a vacation-day spent to belong to exaclty one imperial soldier? Use different tables and the foreign key constraint to set this rule into stone.
You expect a certain parameter not to be NULL? Use specific data types to enforce it (for Oracle-users there’s a great article on making PL/SQL code bulletproof for NULLs by Steven Feuerstein).
I mentioned contract-by-design previously. The functionality to use it (at least to some extent) is built into every mature RDBMS.
Some constraints (especially ones involving different tables) are more complicated to create, but the tools are available. Whenever you have the possibility to eliminate uncertainties, do it! It limits the complexity and things that can go wrong and need to be handled.
I once analyzed a database which contained no constraints besides primary keys and when I asked the developers why, they told me they’d assure everything via “hibernate constraints” inside the middleware.
It didn’t took long until the tables were cluttered with corrupt data and the effort to handle those uncertainties when consuming the data enormous.
A simple example
Let me show a very simple example how we can use a combination of the relational model and constraints to limit uncertainties.
We want to create a name generator for sith and need a table which stores the possible titles a sith can get. We also want to have the possibility to define a specific title as being the default title.
create table sith_title ( id int identity(1,1) primary key, title nvarchar(100), is_default bit default 0 ); insert into sith_title ( title, is_default ) values ( 'Acolyte', 0); insert into sith_title ( title, is_default ) values ( 'Sith', 1 ); insert into sith_title ( title, is_default ) values ( 'Sith Lord', 0 ); insert into sith_title ( title, is_default ) values ( 'Darth', 1 ); select title from sith_title where is_default = 1;
As we can’t be sure that we will get back only one default entry we will have to handle the possibility of multiple default values in every functionality which needs that default title information.
There are several solutions to limit the uncertainty in this case, including triggers, but a very simple one just uses the relational model and a unique constraint:
create table sith_title ( id int identity(1,1) primary key, title nvarchar(100) ); create table sith_title_default ( id decimal(1,0) not null primary key default 1, fk_sith_title integer not null, constraint fk_sith_title foreign key ( fk_sith_title ) references sith_title ( id ), constraint chk_id check ( id = 1 ) ); insert into sith_title ( title ) values ( 'Acolyte'); insert into sith_title ( title ) values ( 'Sith' ); insert into sith_title ( title ) values ( 'Sith Lord' ); insert into sith_title ( title ) values ( 'Darth' ); insert into sith_title_default ( fk_sith_title ) select id from sith_title where title = 'Darth'; select title from sith_title where id = (select fk_sith_title from sith_title_default); insert into sith_title_default ( fk_sith_title ) select id from sith_title where title = 'Sith';
There is still the uncertainty of getting no default value, but we successfully eliminated the uncertainty of getting multiple default values and therefore can skip the handling of that in the consuming functions.
Automated self-testing
Of course “passes the tests” is also about the topic of automated self-testing (which includes unit-, integration-, regression- and all the other kinds of tests).
I wrote about this topic in detail and I’m convinced that including automated tests in your software will be very beneficial to your project in most situations.
But we have to keep in mind, that most automated self-testing (especially if it’s done only on a QA environment and not in production) is just a form of checking what we know.
It can not replace exploratory testing and solely relying on your unit-tests when shipping new functionality might be overconfident. If the software is used by people and is meant to solve problems of people, the “tests” should include them at some point.
Many kinds of tests
Yes, I hate to say it, but when it comes to making sure your application meets your users’ needs, someone needs to think about more than just unit tests of individual procedures and functions.
I hope you will not be overwhelmed by my partial list of other kinds of tests below. Instead, use it to broaden your thinking about what makes software successful.
- Security (SQL Injection, sensitive data, encryption)
- Performance (while there is the possible pitfall of over-tuning, decent performance ist a first class requirement)
- Usability (Is the functionality understandable? Is it easy to use? For whom?)
- Impact on multi-user situations (how will other users be affected, e.g. due to locks?)
- Privacy protection (do I really need to log this? When will it be deleted?)
- Scalability (How will this perform on 100 times the data?)
- Monitoring (How will I notice it doesn’t work as expected?)
- Safety (Will an error in this functionality harm people? How can it be avoided?)
- Concurrency (What happens if two users are using it at the same time?)
- What will happen if the database is going down mid-process?
Each of these things can turn into a necessary requirement and therefore a test our software has to pass.
That’s also the reason why I think that pure unit-testing and TDD is not a sufficient answer to Beck’s rules of simple design. It can be a part of it, but to identify which tests are necessary we need to develop a deep understanding of the problem domain, the people we want to help with our software and also our own environment, possibilities and circumstances.
A compassionate conclusion
Realizing that “passes the tests” might mean more than writing a happy-path unit-test for a function can be overwhelming and even demoralising. There are so many things to consider which sometimes even contradict each other. Maybe this whole thing is arcane knowledge, only available to the most experienced among our profession?
In my opinion Kent Beck’s design rules are a tool. To know them and consider them can be very beneficial in many situations. But they are not the only valid option and they are not a religion you should follow blindly.
Good software design depends. It depends on the problem, it depends on the available resources, on the people who are involved, on the scope and the goal of the project.
And it also depends on the experience of the developer. On the culture of the company. On the quality of the software that already exists.
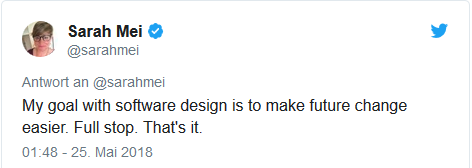
I like this quote very much, because it is pragmatic without the whole arcane, elitist attitude we see so often in the tech industry.
“Passes the tests” can lead to more successful projects, it can help in writing better software and creating better software design.
It can help to reduce suffering of the people involved, be it users, developers, testers or the support team. But if it turns into dogma and starts to cause suffering instead of reducing it, there’s something wrong which should be investigated. And maybe it’s not the right tool for the job.
Great software design, first of all, embraces compassionate code.
https://twitter.com/aprilwensel/status/1004008046840827904
I will happily take baby steps towards that.
[Update, 05.08.2018: Steven Feuerstein gave me a detailed review and helped me to improve several parts, making them express my thoughts better and more understandable. Some new ideas were also added in the process. Thanks a lot, Steven!]

0 Comments