When we face problematic or invalid data in the database and need to fix it, we often need to collaborate with people who know the business context. These people can mostly not work in the database directly, and even if they happen to be also developers (which is usually not the case), it is a good idea to remove all tech struggles and really concentrate on the data alone.
This means that we need to get the data to investigate into an easy-to-read format – and in that matter, Excel is a true superpower. Most people are able to use Excel instinctively, it has very powerful features and provides a clear, frictionless view of the data.

What we want to achieve is to bring our data into an Excel sheet, that we can share with business context folks and then use to correct the invalid data.
Most Database IDEs provide an Export-function to Excel or at least to CSV. The crucial thing in this step is, that we have a column that clearly identifies a row. This is called a unique key.
Often we have a column called “ID” in our database tables, sometimes it is a name or a distinct label that can uniquely identify a row.
If we don’t have such an identifier, the first thing we need to do is to add one, otherwise, our Excel export will not be as helpful as it could be.
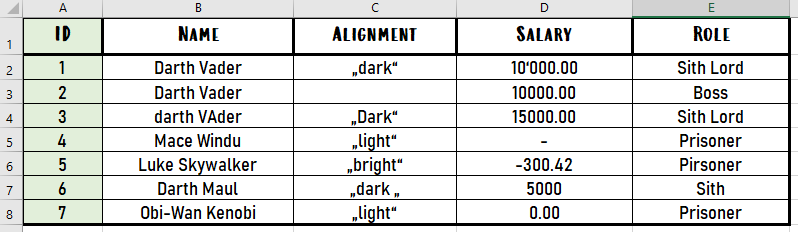
Now we can pass this file around and let the people with business context do the corrections:
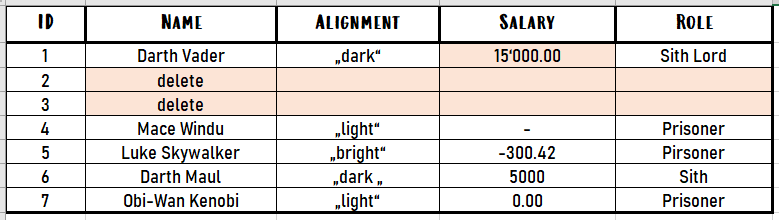
But how do we get these corrections back into the database?
The great thing about Excel is that it provides simple programmability: formulas. With these, we can easily create SQL statements that update the changes back into the database – no matter which database we use (given it supports SQL at least).
We can add a new column and put in the following formula:
=CONCATENATE(
"update deathstar_users set name = '";
B2;
"', alignment = '";
C2;
"', salary = '";
D2;
"', role = '";
E2;
"' where id = ";
A2;
";"
)Note that we put the unique key in the where clause.
(If the unique key consists of multiple columns, we can concatenate them with and)
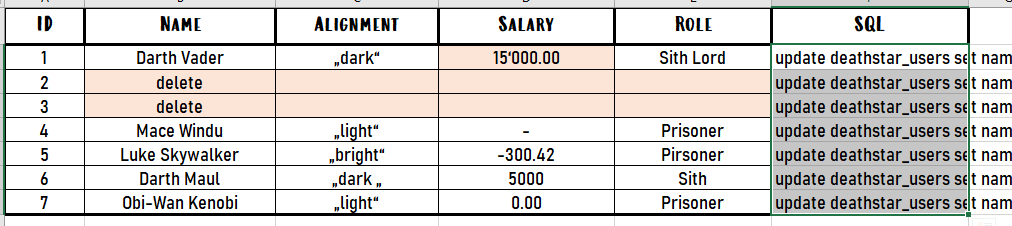
We can now simply select that column, copy it to a text file, and will get the following SQL instructions:
update deathstar_users set name = 'Darth Vader', alignment = '„dark“', salary = '15‘000.00', role = 'Sith Lord' where id = 1;
update deathstar_users set name = 'delete', alignment = '', salary = '', role = '' where id = 2;
update deathstar_users set name = 'delete', alignment = '', salary = '', role = '' where id = 3;
update deathstar_users set name = 'Mace Windu', alignment = '„light“', salary = '-', role = 'Prisoner' where id = 4;
update deathstar_users set name = 'Luke Skywalker', alignment = '„bright“', salary = '-300.42', role = 'Pirsoner' where id = 5;
update deathstar_users set name = 'Darth Maul', alignment = '„dark „', salary = '5000', role = 'Sith' where id = 6;
update deathstar_users set name = 'Obi-Wan Kenobi', alignment = '„light“', salary = '0.00', role = 'Prisoner' where id = 7;
This script can be run against every database.
Let’s add two more instructions to our SQL script
delete from deathstar_users where name = 'delete';
commit;and we’re done.
Of course, there are usually a lot more things to consider, like what if the rows we want to delete have depending entries.
On the other hand, you can also leverage the functionality of Excel a lot more. We could add if-else logic, lookups, and a bunch of other things that a simple “import into database” tool couldn’t do.
The idea to use Excel as a code generator for SQL is – in my opinion – immensely helpful and powerful.
Previous: Example 3: Identify, correct, and prevent duplicate Darth Vaders
Next: Example 4: Identify, correct, and prevent alignment and roles